Paper Review - "Language Models are Few-Shot Learners" (OpenAI's GPT-3 paper)
OpenAI has just released the largest ML model yet, larger by an order of magnitude than the previous record holder. This new model, sensibly named GPT-3 (short for Generative Pretrained Transformer 3) has 175 billion parameters, surpassing Microsoft’s Turing-NLG, the previous largest language model, with its 17 billion parameters.
According to Lambda Labs, a cloud provider, GPT-3 would take 355 years to train on a Tesla V100, the fastest GPU on the market, and would cost $4,600,000 to train on their platform (which they claim has the cheapest rates offered for cloud computing).
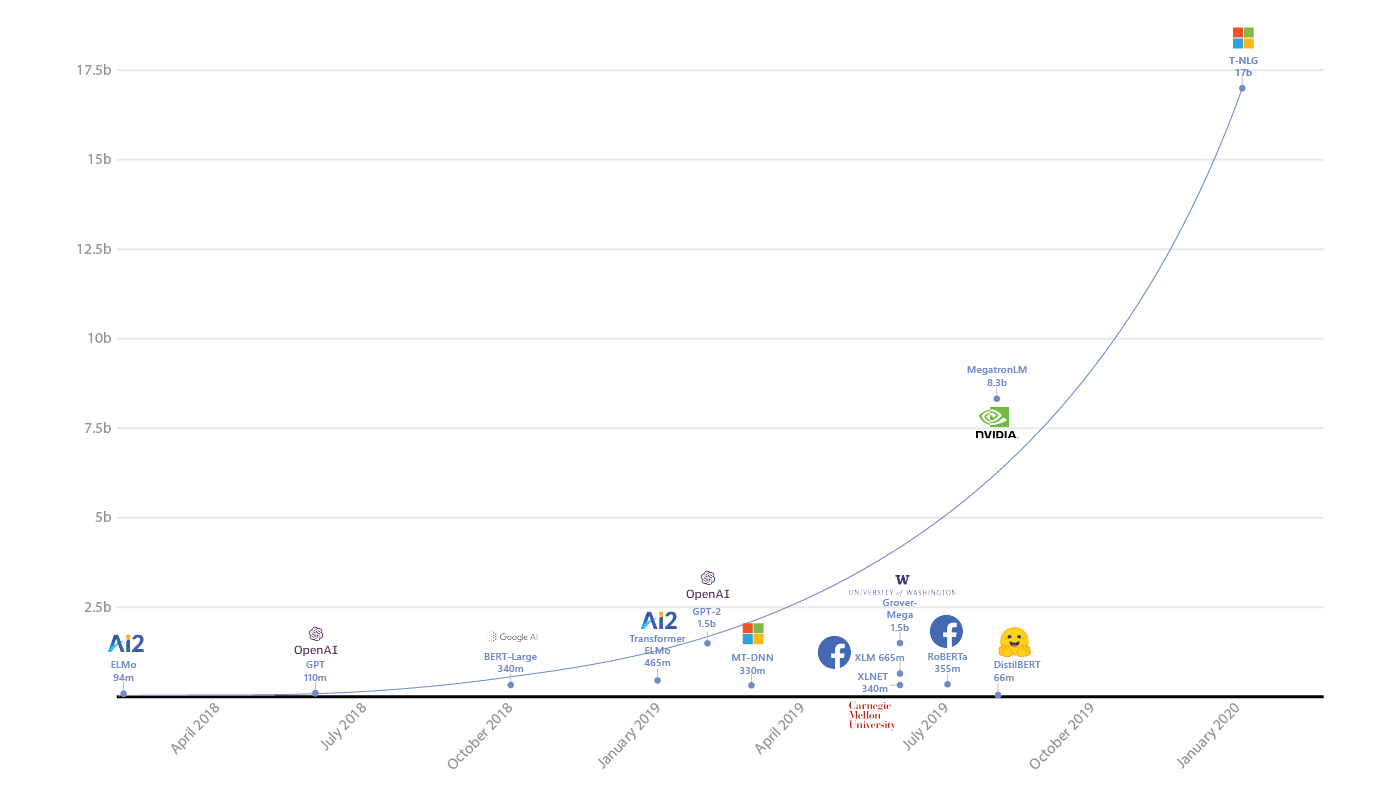
Below you can see a plot comparing the number of parameters for previous language models, which Microsoft compiled for their announcement for Turing-NLG. You can also see in the graph where GPT-2 stands, as well as Nvidia’s MegatronLM, named like that because it was the “biggest, baddest transformer” of its day. GPT-3 would blow up the scale.
The chief scientist of OpenAI, Ilya Sutskever, presented on an interview for Lex Fridman’s Artificial Intelligence podcast a simple intuition on why language models need to be large in order to be good:
In order to predict the next word, when you don’t know anything, you’ll notice very broad strokes, surface level patterns, like… sometimes there are characters and there is space between those characters, you’ll notice that sometimes there is a comma and the next character is a capital letter. Eventually you may start to notice that certain words occur often, you may notice spelling and syntax. And when you get really good at all these, you start to notice the semantics. You start to notice the facts. But for that to happen, the language model needs to be larger.
After being debuted on a 2017 paper on machine translation, the Transformer architecture has revolutionized the field of NLP. The previous state-of-the-art in language model architecture, Recurrent Neural Networks (specifically LSTMs), while showing potential, was severely limited by its recurrent nature, in the sense that it was not very parallelizable. The Transformer, with its attention mechanism, presented a solution to this lack of parallelization. This may have been its greatest breakthrough, since it allowed for the training of much larger language models.
In this post, we’ll be taking a look at the recently released paper for GPT-3. Most of the paper is presentation of the results and capabilities of this model, and most of the article will also be on that. For a more detailed look, check out the paper.
Architecture of GPT-3
As for the architecture, there is nothing too new here, since it’s essentially the same as the previous GPT-2, though much larger. For a detailed description of the GPT-2 architecture, check out Jay Alammar’s fantastic post The Illustrated GPT-2. Remember, GPT-2 was said to be “too dangerous for the world” at the time of its release. It only has 1.3 billion parameters, a very small number when compared to the 175 billion of GPT-3. The point of GPT-3 is not to experiment with a fancy new architecture, but to go big.
Language Model as Few-Shot Learner
Perhaps the most surprising new capability of GPT-3 is the fact that it managed to beat the state-of-the art in some NLP tasks with no fine-tuning. Previous language models have shown great capabilities in a number of tasks, like question answering or text summarisation. However, in order to perform these tasks (which are different from the normal text generation language models are trained to do) the models must be fine-tuned specifically for each individual task. This requires having training and test datasets for the new task, as well as additional compute.
In the paper, no fine-tuning was performed on GPT-3. However, three different situations were experimented: no-shot, single-shot and few-shot learning.
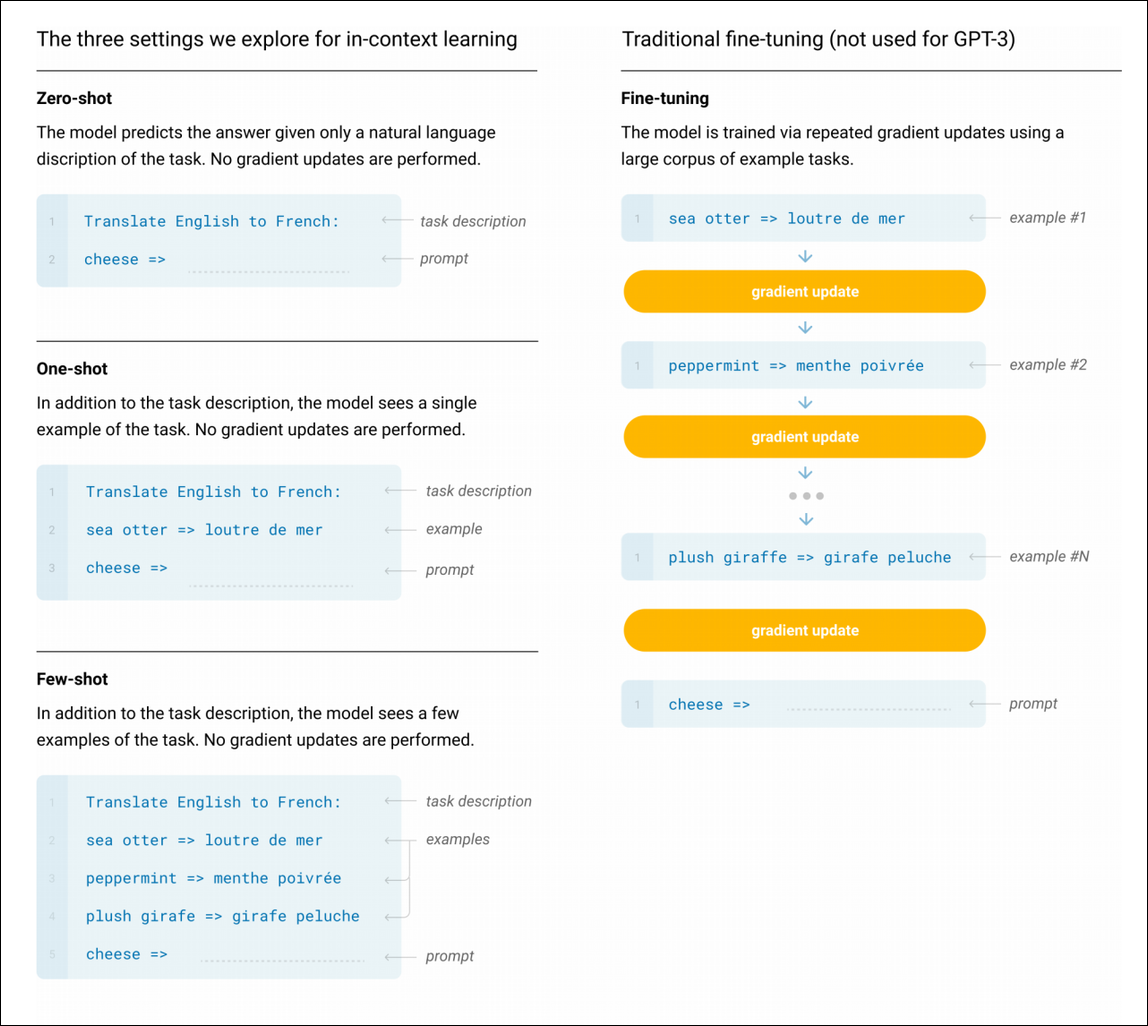
As you can see, the task settings are provided to the language model simply as sentences for it to complete, with no gradient updates whatsoever. In the zero-shot setting, only a description of the task is provided. In the single-shot setting, the model is provided with a simple example of the task to perform (in the case of English to French translation, this single example is an English-French pair). For the few-shot setting, several examples of the solved task are provided, as part of the expression the language model must complete. Using this few-shot method of understanding tasks, GPT-3 managed to break the state-of-the-art in several different tasks, surpassing previous models, which had been fine-tuned for those specific tasks.
So how good a language model is it?
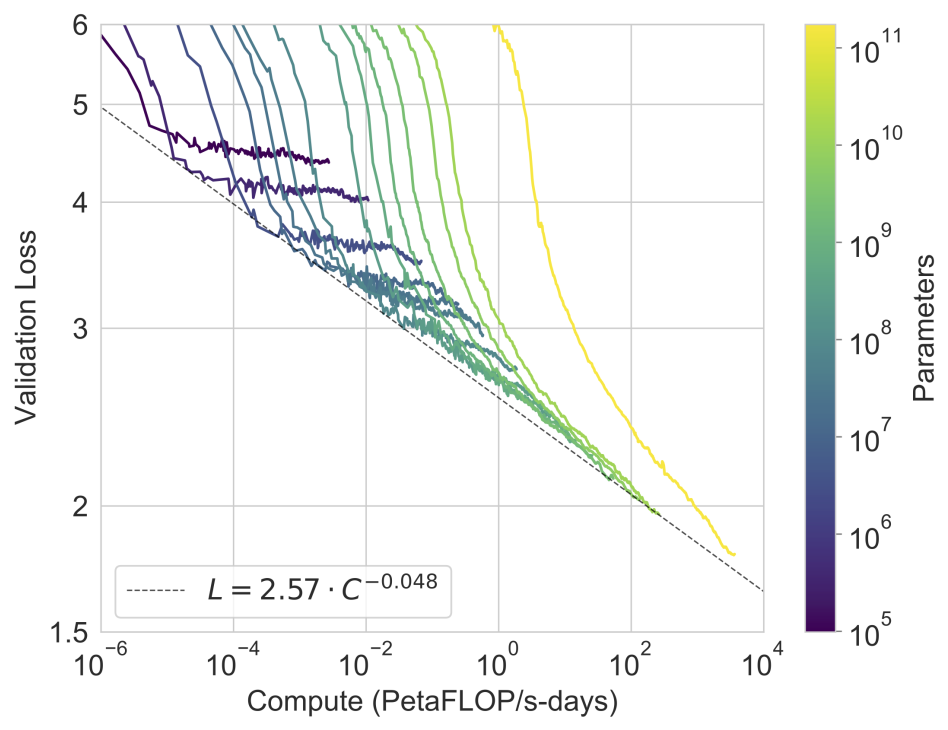
It has been verified by past experiments that as the number of parameters is increased in language models, the validation loss (calculated used log probability, a.k.a. perplexity) decreases. Essentially, as model size, compute time and dataset size increase in the same fashion, a power law is followed where the model will get better. A question still to be answered is: how far can this take us? It seems like, at 175B parameters, the limit hasn’t yet been discovered, since GPT-3 is still in this trend of improvement. It follows that, if size was increased further, we could still expect some improvement on results.
Analysis of Results
In this section, we’ll go over some of the results I found the most interesting in this paper. We’ll cover most of the presented results, though not all, so this post doesn’t get too long.
Question Answering
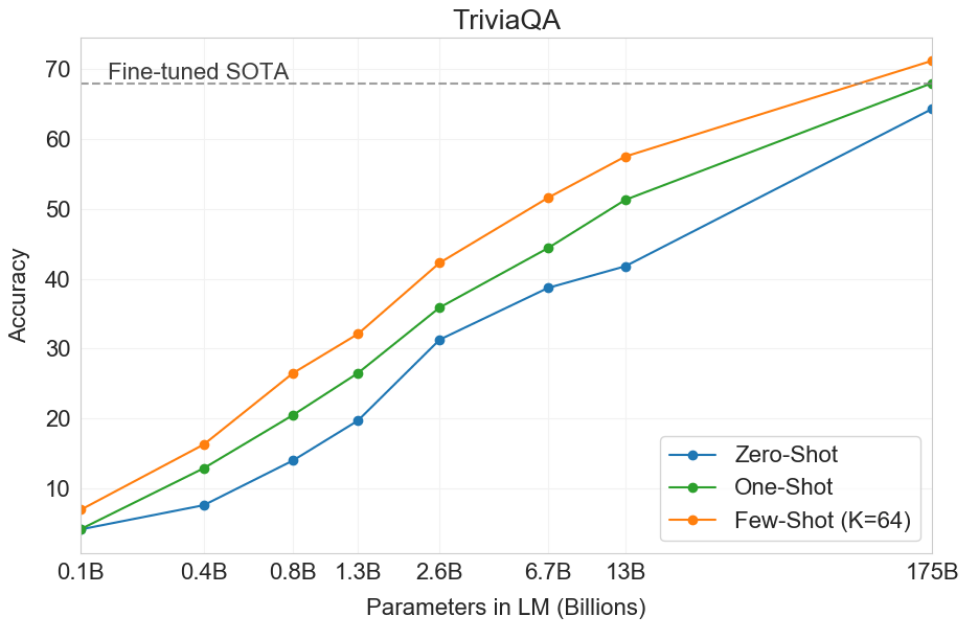
The first task OpenAI analyses in the paper is question answering. In this test, GPT-3 either gets a question, or context followed by a question. The model should either simply answer the question or choose from several options which one is the most likely to be correct. In these tasks, the model can not query any outside information, we simply want to know the information that is encoded in the model’s 175B parameters. In some of these question answering tasks, GPT-3 managed to outperform a fine-tuned SOTA model in both the one-shot and few-shot settings. Another interesting point is that some of the SOTA models are Open Domain (vs. Closed Book) which means that they can access websites like Wikipedia. The question-answering tasks where GPT-3 couldn’t beat the SOTA (e.g. NaturalQS) were tasks that depended mostly on factual knowledge, where open domain models have the advantage.
Note how the performance in a question answering task increases with the number of parameters. This makes sense intuitively, since a larger number of parameters allows for the encoding of more information.
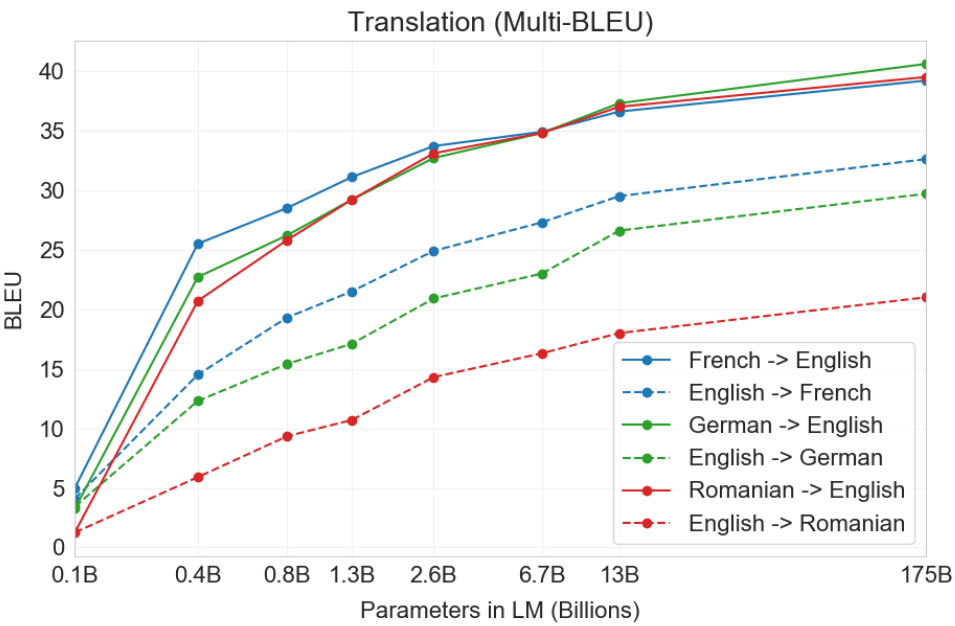
Translation
For tasks in translation, the performance also increases with the number of parameters. In translation tasks, GPT-3 showed its best performance when translating into English, be it in no-shot, one-shot, or few shot settings. This makes sense, considering most of the corpus the model trained on was in English, and GPT-3 was intended from the start to be an English language model. The performance when translating from English to other languages is therefore not as good. When translating from other languages into English, the model maintains similar performance across languages, but that is not the case when translating from English into other languages, in which case the performance varies significantly across output languages. In some cases, GPT-3 managed to improve on the current supervised SOTA when translating into English.
Winograd Schemes
Winograd is a classic task in NLP, which involves figuring out which word a pronoun refers to, in cases when the pronoun is grammatically ambiguous but semantically unambiguous to a human. In some Winograd-Style tasks, GPT-3 managed to beat the fine-tuned SOTA performance in all its three settings (even no-shot), while for others it comes close.
In earlier Winograd-Style tasks, the SOTA is close to human performance, while for newer, more adversarial tasks, there is still some distance between the current best AI performance and humans. In more adversarial tasks, there were bigger differences between no-shot and few-shot performance for GPT-3.
Commonsense Reasoning
Several tasks were tried in order to evaluate GPT-3’s capacity for reasoning. The three analysed datasets attempt to capture physical or scientific reasoning. They are not tasks of sentence completion, reading comprehension, or broad knowledge question answering. In one of the tasks (PIQA, comprising common sense questions about the physical world, which tries to evaluate for a grounded understanding of the world) GPT-3 in the no-shot setting managed to beat the current fine-tuned SOTA, while for the other two it didn’t. However, in the case of the PIQA dataset, the authors claimed that there is possible contamination in this dataset, meaning that a portion of this dataset might be in the training dataset of GPT-3. This was only noticed after the training.
Reading Comprehension
To test GPT-3’s reading comprehension, 5 datasets were used, which include abstractive, multiple choice, and span based answer formats in both dialog and single question settings. GPT-3 couldn’t beat the fine-tuned SOTA in any of these tasks, and performance varied across datasets.
Synthetic Datasets
Given the way that GPT-3 is tested (simply giving it some text to complete) it’s easy to devise new tasks for it to solve. No training datasets are required, which is an advantage that comes from performing no fine-tuning. In order to evaluate GPT-3 further, OpenAI devised some additional tasks, and it intends to release the test datasets soon. The tasks we’ll go over next are not benchmarks, but ad-hoc tasks OpenAI devised to test GPT-3.
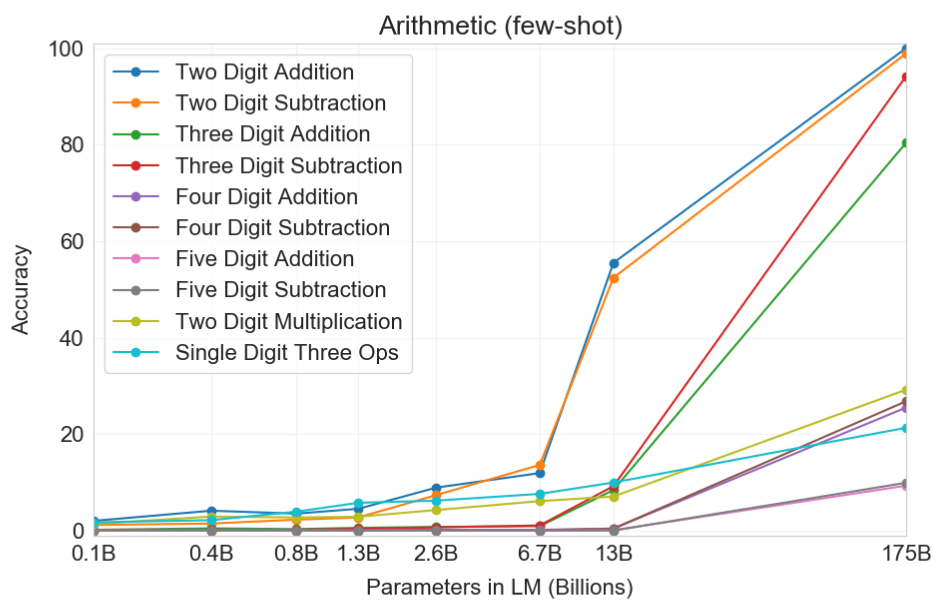
Arithmetic Expressions
It turns out that GPT-3 is quite good at arithmetics, especially in two-digit addition and subtraction, which it’s able to consistently perform. Three digit addition and subtraction is also surprising, with over 80% and 90% accuracy respectively. Keep in mind that GPT-3 is a language model, not a calculator, and that it learned arithmetics simply by analysing text. Results for arithmetics above three digits and for multiplication were not as good. As can be seen in the image, arithmetics is a capability only shown by very large models.
One-shot and zero-shot performance are somewhat degraded relative to few-shot performance, suggesting that adaptation to the task (or at the very least recognition of the task) is important to performing these computations correctly. Nevertheless, one-shot performance is still quite strong, and even zero-shot performance of the full GPT-3 significantly outperforms few-shot learning for all smaller models.
SAT Analogies
Another task OpenAI came up with to test GPT-3 were SAT questions. The specific questions chosen were the analogy problems, which are multiple choice. Questions of this kind were present on the SAT (the exam Americans have to take to attend university) before 2005.
A typical example is: Audacious is to boldness as
- (a) sanctimonious is to hypocrisy,
- (b) anonymous is to identity,
- (c) remorseful is to misdeed,
- (d) deleterious is to result,
- (e) impressionable is to temptation.
The student is expected to choose which of the five word pairs has the same relationship as the original word pair. In the previous example the answer is “sanctimonious is to hypocrisy”.
It’s interesting that GPT-3 managed to beat the average among college applicants in both the one-shot and few-shot settings. The college applicants’ average was 57%, while GPT-3 scored 62.5%, 59.1% and 53.7% in its few-shot, one-shot and no-shot settings, respectively.
News Article Generation
One of the most talked about capabilities of GPT-2 was the generation of quality artificial news articles. In order to test GPT-3’s ability to generate news articles, OpenAI set up a test in which humans unaffiliated with OpenAI try to discern articles generated by GPT-3 from real, published news articles. The generated articles were chosen and formatted programmatically, in order to prevent cherry-picking by the developers, and it was verified they were not present in the training data. A control study was also set up, to try and evaluate the human’s effort and attention. For this control study, a 160M parameter “control model” was developed which had no context and increased output randomness. In essence, this model generated purposefully bad articles.
For each model, 80 participants tried to discern the source of news articles, some of which were generated by GPT-3. OpenAI claims the corpus GPT-3 was trained on has relatively few news articles, so it was found that it couldn’t generate articles in a no-shot setting, since it would e.g. generate twitter conversations instead of articles, when provided with “News Article:” plus a title as prompt to complete. The news articles had then to be generated in a few-shot setting, by providing three news articles as prompt.
As for results, GPT-3 is excellent at generating realistic news articles. While mean human accuracy (the ratio of correct assignments to non-neutral assignments per participant) for the “control model” was ~86%, and chance would be 50%, humans managed to discern GPT-3’s articles from real ones at ~52%, which is barely above chance. Past work had pointed that humans tended to discern generated articles more accurately if they were longer. In order to test this, a second, similar test was set up, in which the articles were ~500 words long (in the first test they were ~200 words long). Even with longer articles, mean human accuracy was still ~52% for the GPT-3 articles.
Below you can see the article which humans found the easiest to distinguish from a human written article. It provides factually wrong information (e.g. Megyn Kelly does not host The Tonight Show, and this interaction between high-profile celebrities never happened). It’s also quite a bizarre, funny read. Nonetheless, it is correct syntactically, and some coherence is maintained across the article.

Training Set Contamination
Given that GPT-3 was trained in a large portion of text extracted from the internet, some of the text in benchmark tests was present in the training set. This must be accounted for when training language models, but becomes as even bigger concern in a super-large model such as GPT-3. However, also due to the large amount of data, GPT-3 does not come close to overfitting on its training data, which reduces the effects of this problem.
While OpenAI tried to remove the overlap between the training set and the benchmark tasks, a bug prevented the full removal. Since the model is so large, and training is such a lenghty, expensive process, it wasn’t feasible to retrain. While there was a degree of contamination for most of the benchmark tasks, OpenAI analysed the problem in several different ways, but they claim much work remains to be done in the field of contamination analysis.
In the rest of the paper, OpenAI presents some thoughts on the limitations and impacts of GPT-3 (such as an analysis of bias and fairness, and the model’s energy usage), as well as some related work.
In conclusion, OpenAI has just moved the state-of-the-art in NLP. It was very interesting for me to understand what a model of this size can do, and what it can’t. It’s obviously not an AGI, but I found its capabilities surprising on some tasks. The paper is very clear and well composed, so I advise you to check it out :).